近日,清华大学联合西安交通大学人工智能与机器人研究所(以下简称人机所)、上海大学、北京理工大学等单位,在提升大语言模型可靠性研究方面取得新进展。研究团队提出了一种超图驱动的检索增强生成方法Hyper-RAG,用于缓解大语言模型在垂直领域应用中的“幻觉”问题。相关成果以“Hyper-RAG: combating LLM hallucinations using hypergraph-driven retrieval-augmented generation”为题,发表于国际著名期刊《自然·通讯》(Nature Communications)。
在该研究中,西安交通大学人机所郑南宁院士和团队成员杜少毅教授、博士生胡浩、硕士生侯星梁和刘石全都深度参与了方法设计与实验验证工作。清华大学博士后丰一帆、人机所博士生胡浩和上海大学应时辉教授为本文共同第一作者,人机所郑南宁教授、杜少毅教授、北京理工大学胡晗教授以及清华大学高跃教授为本文共同通讯作者。
大语言模型(Large Language Models, LLMs)在面对医疗、法律、金融等垂直领域知识问题时,常常会生成偏离既定事实的回复或模糊不清的回答,从而带来潜在应用风险。检索增强生成(Retrieval-Augmented Generation, RAG)通过构建特定领域知识库,采用基于向量的检索技术提取与给定查询相关的信息,使LLM能够生成更准确、更可靠的内容。然而,传统RAG和现有基于图的RAG方法受限于实体间“两两关系”的表示方式,难以刻画多个实体同时参与的复杂高阶关联,例如多因素共同影响下的疾病机制、多证据链之间的关联关系以及多人物的同时交互等。这使得关键知识在结构化过程中被弱化甚至丢失,进而影响检索结果的完整性和生成内容的可靠性。
为解决这一难点,研究团队提出 Hyper-RAG,将超图计算融入 RAG 框架。与传统图不同,超图中的一条超边可以同时连接多个实体,能够同时捕获原始数据中的成对低阶关联和群组高阶关联,从而构建更加全面、结构化的领域知识表示,最大限度减少知识结构化过程中的信息损失。Hyper-RAG 通过超图结构实现相关知识的精准召回与扩散,为大语言模型提供更加丰富、完整的事实依据,也为医疗诊断、金融分析等高可靠需求应用提供有力支撑。
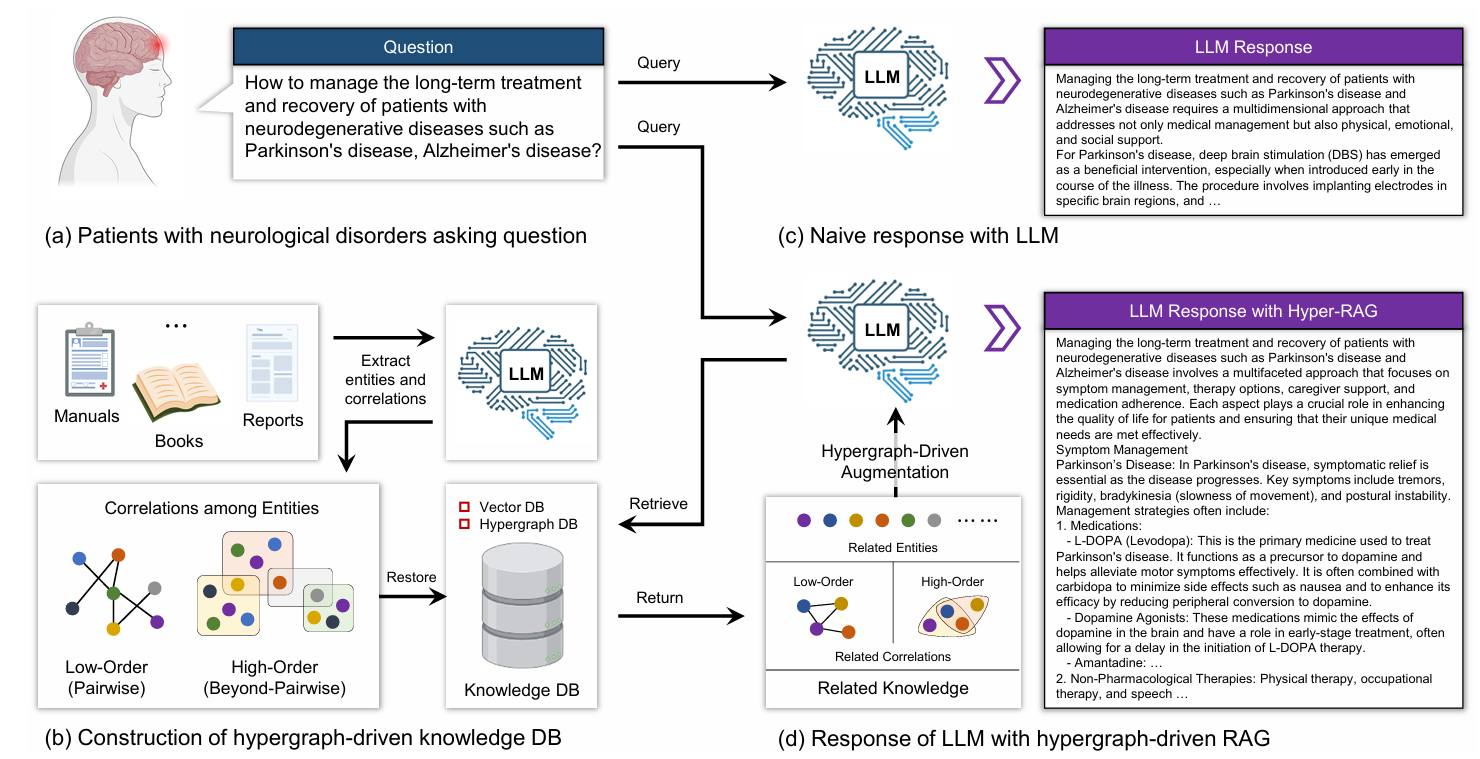
图1. Hyper-RAG结构示意图
研究人员在覆盖神经科学、病理学、数学、物理学、法律、艺术等 9 个不同领域的数据集上开展实验,采用 6 个不同大语言模型、2 种评估策略以及多维评价指标进行全面验证。实验结果表明,与现有基于图的 RAG 方法相比,Hyper-RAG基于超图计算突破传统图结构难以建模高阶关联的桎梏,建立覆盖全尺度关联的领域知识库及知识超图谱,降低关键知识缺失60.7%,降低大模型幻觉48.5%,在多个任务中均表现出更优异的性能,能够有效捕捉复杂的多实体群组高阶关系,显著提升生成内容的准确性与可靠性。
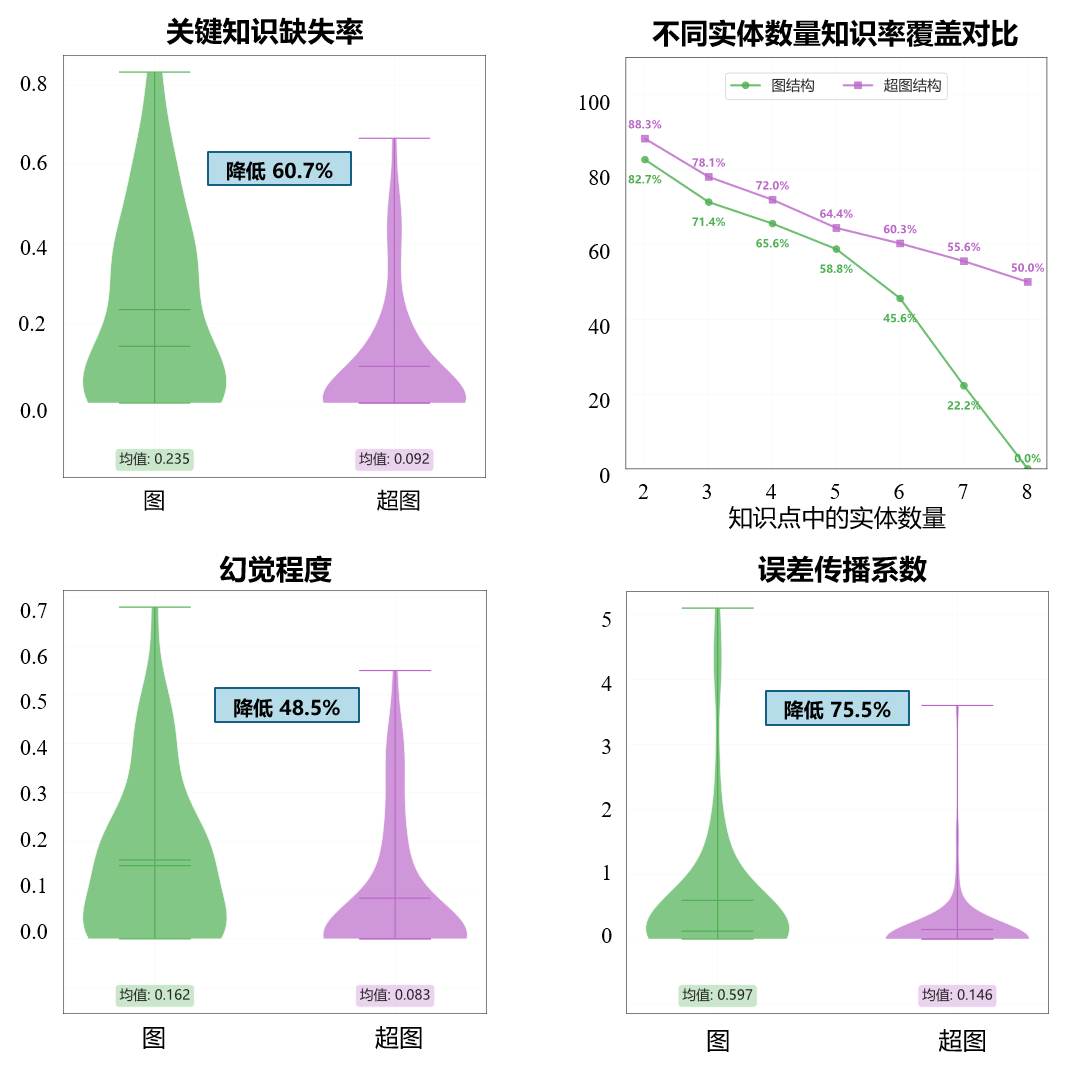
图2. 图和超图RAG知识获取能力对比
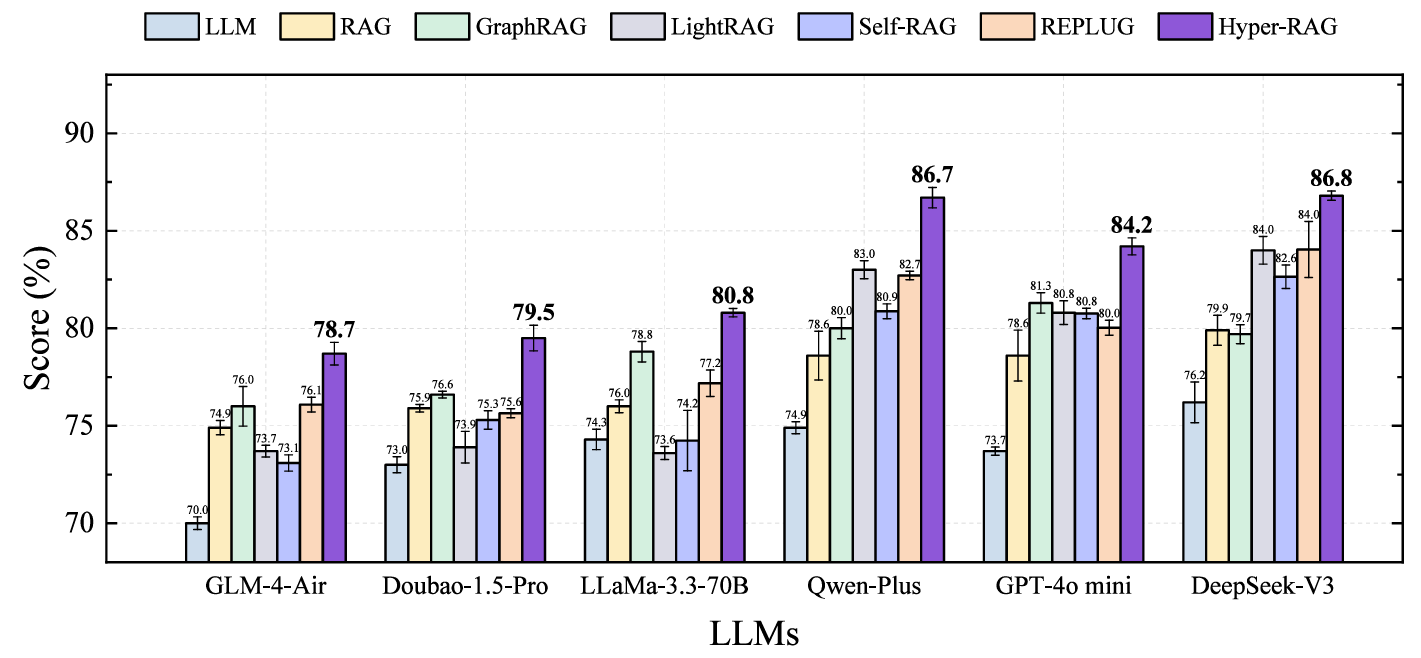
图3. Hyper-RAG 在不同LLM的实验结果
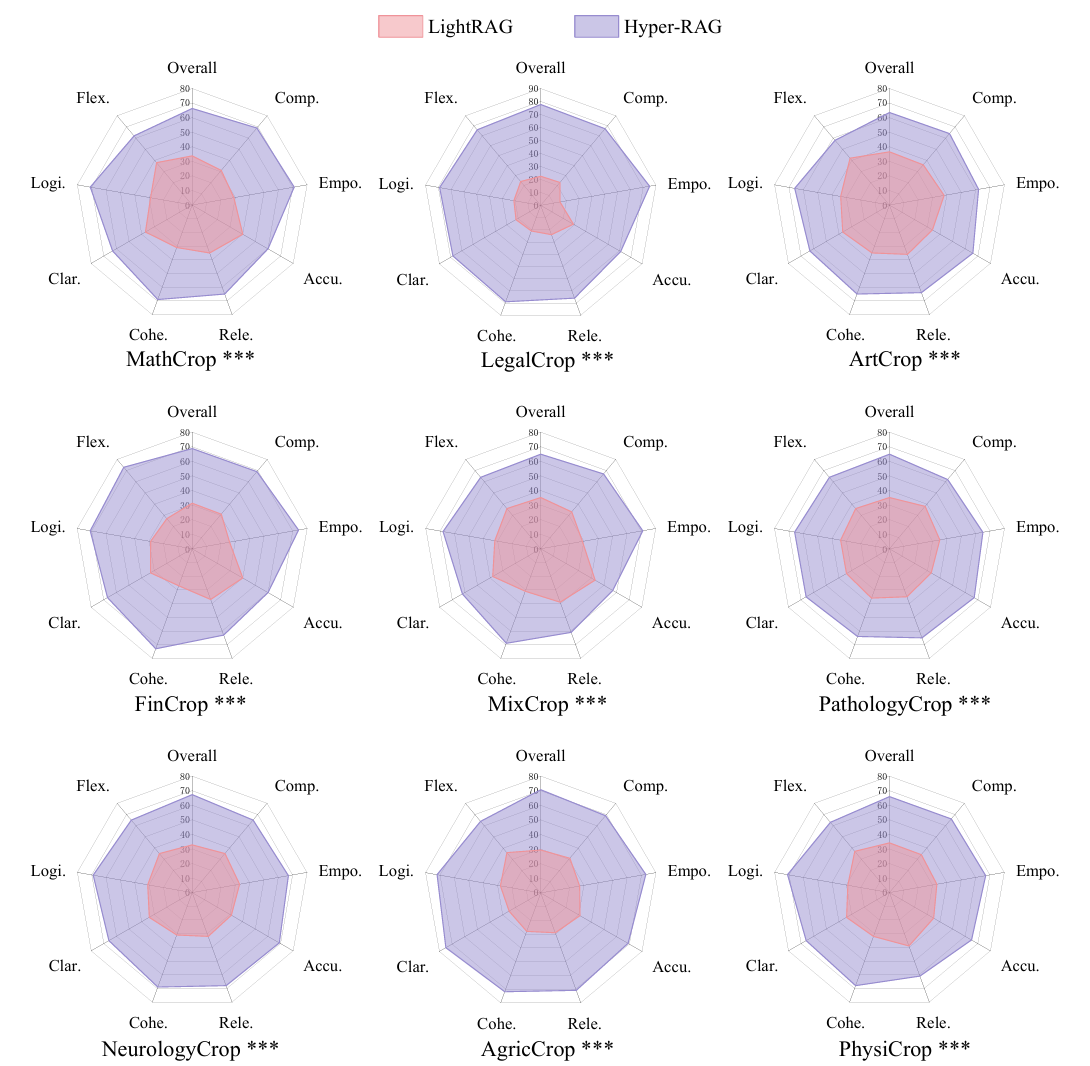
图4. Hyper-RAG 在不同领域数据集下的实验结果
该研究为缓解大语言模型幻觉问题提供了一种新的知识表示与检索范式。Hyper-RAG 通过基于超图计算的知识建模与检索机制,为医疗诊断、金融分析、科学问答等高风险场景下的大语言模型应用提供了有力支撑,也为推动更加可靠的AI4Science与AI4Health落地提供了新的技术路径。

图5. 论文在线发表页面
论文链接:https://www.nature.com/articles/s41467-026-71411-1
代码链接:https://github.com/iMoonLab/Hyper-RAG





